Use this forum topic to ask questions or bring up any issues you have with the hackathon.
I tried to start the hackathon but the virtual machine did not have the directory “2025_hackathon”. What’s wrong?
Hi Professor. Welcome to the hackathon! When you first start the virtual machine, it populates the file system with all the code you need to get started, but this can take a while. Leave the machine running for about 10 or 15 minutes and all the needed data will show up.
Hi JH.
We were having issues with the original setup, so we made a change. You should see this in the “Virtual Lab Instructions”. There is a link to these instructions above the “start” button where you launch the VM.
What you want to do is run the script “unpack.csh”. You do this by entering the command:
% source unpack.csh
This will create the 2025_hackathon directory for you.
Let us know if you have any further issues.
Thanks!
-Russ Klein
Hi, RussK
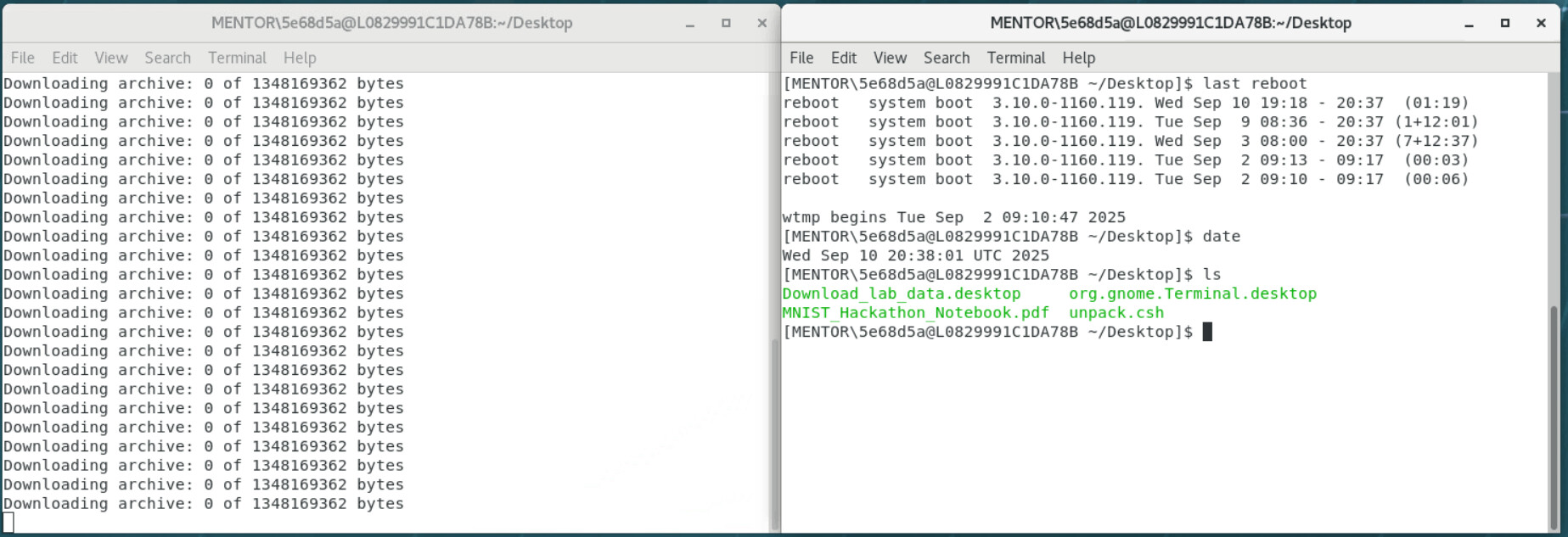
The left side of the screenshot I uploaded earlier shows what happened when I sourced unpack.csh, but it didn’t work.
In the unpack.csh script, when file_size is smaller than expected_size, it simply prints the file size of 2025_hackathon.tgz every 10 seconds. It seems that the script is not downloading the file directly (e.g., via wget), but instead is waiting until the file system mounts or makes the 2025_hackathon.tgz file available.
Could you take a look and confirm?
Thanks!
- JH
The disk image failed to fully load. I will forward the issue the IT folks for these VMs.
I hope to give you answer soon.
Regards, RussK
I figured that the issue was the download link not working in the VM (https://wiki.vlabs.mentor.com/display/VLG/Catapult?preview=/64684049/64684052/2025_hackathon.tgz )
It takes us to an error page on confluence. That tar must be downloaded for the unpack script to work. Hopefully it’s fixed soon.
The issue got resolved. I can download the tarball using the shortcut on the Desktop now.
Can we get an updated leaderboard?
Thanks!
Hi Ornulu, we do not have any new submission to add to the leader board. Once you complete the hackathon, submit your results. If you’re having issues with this, you can e-mail the same data to me at Russell.klein@siemens.com. Thanks and good luck.
The submission form can be found at the bottom of this page (click here), if you are logged in with a full-access account too!
Thank you for the quick response and encouragement. I’ll try to complete the hackathon and submit my design.
Is there a limitation in the virtual lab infrastructure that we can’t launch virtual labs for two learning paths at once? I think I launched a virtual lab for “Catapult C++ basics and HLS” path and when I came back to launch my virtual lab for the hackathon, it spun up a completely new VM and I lost all my saved files and progress. I’m restarting from my python model again now ![]()
I apologize for the loss of your work. I know this can be frustrating. I’ll check with the IT teams on this. I was unaware of the limitation related to running multiple virtual labs.
Keep at it!
-Russ
Can we make multiple submissions?
I have one design ready which I haven’t optimized fully, but it’s still decent enough. I’d like to be able to submit it first, then go to town on it and submit again.
Thanks!
My RTL simulation keeps getting stuck after the last layer
timestamp("layer #4");
float softmax_in[10];
float softmax_out[10];
copy_from_cat(memory, softmax_in, 35082, 10);
softmax(softmax_in, softmax_out, 10);
timestamp("end");
memcpy(probabilities, softmax_out, 10 * sizeof(float));
return 0;
}
I get the output layer #4 == xxxx
but then nothing for a long time and I have to kill the simulation. Per the Notebook this softmax should take ~30us sim time only.
How do I go about debugging this?
Edit: After adding a bunch of timestamps, I isolated it to the copy_from_cat() function. My PAR_IN is 2 if that helps.
No. There is a limit of one entry per person. Get the best result you can. And good luck.
-Russ
My suggestion was going to be to add printf() or timestamp statements to determine which function was stalling (which is exactly what you did). copy_from_cat can take a long time, but in this case you are only copying 10 values, which should complete very quickly. As long as you have not placed data outside of the physical memory, the copy operation should complete quickly. Your offset of 35,082 is small enough that it is inside the memory. How large is your weight database?
-Russ
Oh No!
In that case, would it be possible to withdraw my current submission?
It’s quite small. The weights_float.h is 540k and the inference.mem is 142k only.
after spending some more time debugging I zeroed it to this function in cat_access.cpp.
float get_cat_value(cat_memory_type *memory, int offset)
{
printf("in get_cat_value\n");
unsigned int index = offset / PAR_IN;
unsigned int slice = offset % PAR_IN;
unsigned int shift = slice * WORD_SIZE;
unsigned int array_word = memory[index];
unsigned int bits;
int neg = 0;
float value;
#if (WORD_SIZE==32)
unsigned int mask = 0xFFFFFFFF;
#else
unsigned int mask = (1 << WORD_SIZE) - 1;
#endif
printf("array word: %x \n", array_word);
bits = (array_word >> shift) & mask;
if ((bits>>(WORD_SIZE-1)) & 1) neg = 1;
if (neg) bits = ((~bits) + 1) & mask;
printf("word read: %x \n", bits);
value = ((float)(signed int) bits)/((float)(1 << FRACTIONAL_BITS));
if (neg) value = value * -1.0;
printf("value returned: %d \n", value);
return value;
}
with these printfs I get this in the console.
layer #test == simulation time=8065 us (elapsed=0 us)
float copy not on host // from copy_from_cat
in get_cat_value
array word:
So the program on the embedded just hangs up on the read from memory.
Is anyone else experiencing this? Any help is appreciated!