Pipelining
Pipelining means how often to start (the next) iteration of a loop or a function in High-Level Synthesis (HLS). It is defined with an Initiation Interval (II). The default II is generally 1, often implying continuous clock-by-clock throughput and minimal latency. However, in some cases, an Initiation Interval greater than one may be used, which can increase latency and is often due to resource constraints, feedback dependencies, or memory competition.
-
Pipelining Resources
-

-

-

Optimizing SystemC/C++ Hardware Architectures Through High-Level Synthesis
Pipelining Jun 22, 2018 Webinar
-
-
Pipelining Overview
Pipelining Introduction
Pipelining is how often to start the next iteration of a loop or a function in HLS. It is defined with an Initiation Interval (II). The default II is generally 1 to obtain continuous throughput. However, in some cases an II of 1 will not always be possible due to resource constraints, feedback dependencies, memory competition. The II value is set in HLS either using directives or pragmas.
Loop Pipelining
Loop pipelining is how often to start the next iteration of a loop. This is used along with loop unrolling and loop merging. In fact, after the above two optimizations are complete, the scheduler in HLS uses pipelining constraints to build a pipelined loop. Pipelining does not occur when the loop is optimized away due to the above two optimizations. It is ideal to pipeline loops when:
- Loop has poorly utilized resources
- If loop has many iterations, it is ideal to use it to improve throughput.
Loop Pipelining is not the same pipelining used in RTL. Loop pipelining is similar to the pipelining done in CPUs where the second iteration/operation is started before the first one finishes. If loops are nested, internal loops can be pipelined to reduce latency. The outermost loop can be pipelined to produce a throughput driven design.
The scheduler applies the pipelining constraints to build a pipelined loop. Just like in loop unrolling, loop pipelining is limited by the looping dependency chains in any loop.
HLS tools automatically analyzes the design to determine the distance from the write-to-read to verify that the scheduling in the design is correct. The tools add a constraint between the write and the read to keep the scheduling correct. The tool only considers one iteration. This applies to any looping dependencies in a design.
An example can be seen in this image below:

Conditional Data Dependencies in Pipelines
Conditional data dependency refers to a dependency that might not occur in every iteration of the pipeline because of conditional logic in the loop body. For example, the following loop iterates 100 times, but the assignment to 'temp' only occurs every 2nd iteration. Furthermore, the first multiplication operation is dependent on the value of temp from the 'previous' assignment.
int temp; for (i=0; i<100; i++) if (i%2 == 0) temp = temp * input_1 * input_2;In this example, if the initiation interval (II) is set to 1, the normal scheduling algorithm would attempt to schedule MULT operations in every clock cycle. But the data dependency does not allow that. Instead, the scheduler automatically adjusts the schedule to compensate for the data dependency. The MULT operations in this case, are scheduled in every other clock cycle, as shown in the following illustration:
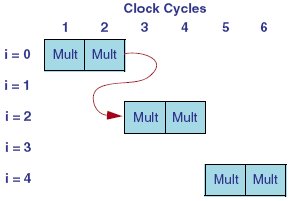
Nested Loop Pipelining
Setting the pipeline initiation interval (II) on a set of nested loops will NOT unroll the loops inside. Instead, the innermost loop is pipelined with the correct initiation interval and the loops around that loop are flattened. The result is that the innermost loop cycles always start based on the initiation interval. This is useful for algorithms that need to have a continuous throughput, and that are easy to describe as a set of nested loops.
Example is seen in the image below:
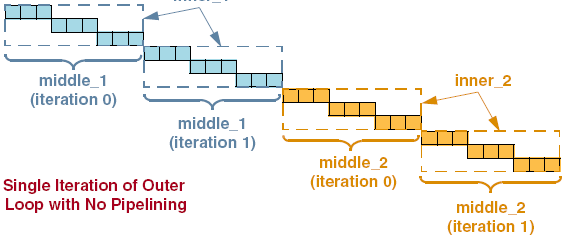
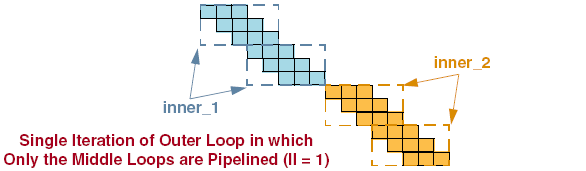
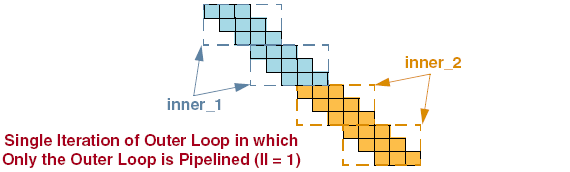
Stalling of Pipeline
When the pipeline does not have input variables, the pipeline should stall. This can happen in different ways:
- Stall (default): The input data is not available and the pipeline will stall. Previous iterations with the needed data will not flush.
- Flush: The design will not stall when data is not available. Previous iterations with needed data will flush. Bubbles will not compress and the output which does not take new data will stall at stages before it.
- Bubbles: Same as flush but the bubbles will be compressed.
Scheduling Failures
Resource Competition (Memories): Occurs due to impossible constraints for e.g. pipelining a design so that it attempts to read a single port memory more than once in a clock period. Pipelining with II=1 will most likely lead to resource competition failures as there might be writing/reading of 2 different addresses as they would belong to different iterations.
Data Feedback Dependency Scheduling Failures: Scheduling will fail if the design contains feedback, and the feedback timing path is greater than the initiation interval. This can arise especially when pipelining with II=1 and unrolling loops in the design, along with bad coding style
Conclusion
Pipelining is how often to start the next iteration of a loop or a function in HLS. It is defined with an Initiation Interval (II). The default II is generally 1 to obtain continuous throughput. Scheduling failures can occur when loops are pipelined with an II lesser than the actual latency of the loop. Pipelines can also be stalled in different ways when an input is not available.
Pipelining helps improve latency and throughput in HLS designs.